
DeepSeek’s R1 had it’s time in the spotlight as a strong reasoning model that came ‘out of nowhere’. One of the highlights of the model was that it was released publicly, including both the training process and weights. However, one thing lacking from the paper was an overview of the pipeline. Unsurprisingly, there are a few steps involved to produce such great results.
The below diagram from the DeepSeek Community, showcases this in its entirety.
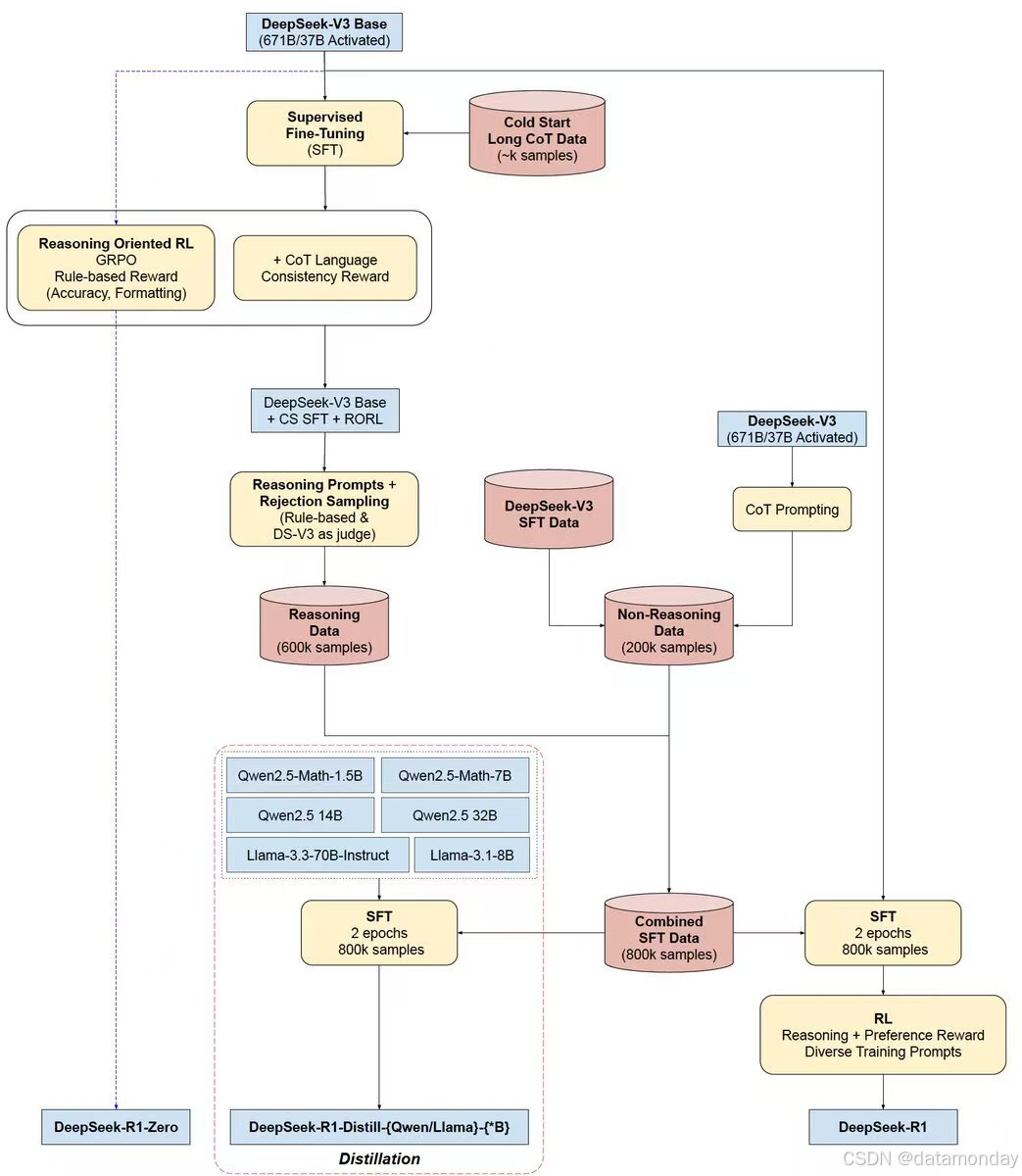
In addition to the diagram, a quick summary is provided below:
DeepSeek-R1 is trained through a four-stage pipeline that builds on DeepSeek-R1-Zero, which itself was trained purely via reinforcement learning (RL) without any supervised fine-tuning (SFT). While R1-Zero demonstrated strong reasoning skills, it suffered from readability and language-mixing issues.
To address this, DeepSeek-R1 introduces a hybrid method combining cold-start SFT and multi-stage RL:
- Cold Start: The base model (DeepSeek-V3) is first fine-tuned on a small, curated dataset of long Chain-of-Thought (CoT) examples. These are collected via few-shot prompting, readable outputs from R1-Zero, and human-edited generations.
- Reasoning-Oriented RL: After cold-start SFT, the model undergoes RL using GRPO (Group Relative Policy Optimization). Rewards include both accuracy (rule-based, e.g., for math and code) and language consistency to reduce multilingual artifacts.
- Rejection Sampling + SFT: When RL converges, the model is used to generate new training data (600K reasoning, 200K non-reasoning), which is filtered and used for another SFT phase.
- RL for All Scenarios: A final RL stage aligns the model with human preferences across domains (e.g., helpfulness, harmlessness), using a mix of rule-based and learned rewards.
The result, DeepSeek-R1, matches or surpasses OpenAI o1-1217 on many reasoning benchmarks. Its outputs are structured, readable, and aligned. The team further distills R1 into smaller models, demonstrating that reasoning capabilities can be transferred effectively without running RL on small models directly.
It’s great to have such detailed training pipelines to help the research community, it’s a great research paper.