
LLMs have grown from 200M parameters up to the estimated 6T parameter models we see today - a factor of 10,000 - let’s explore what innovations made that possible by stepping through the largest models at the time and their specific innovations.
The key models are listed below:
- Claude Opus 4, Params: 6000M, Release: May 2025
- GPT-4.5, Params: 3000M, Release: Feb 2025
- Claude 3 Opus, Params: 2500M, Release: Mar 2024
- GPT-4 Classic, Params: 1760M, Release: Mar 2023
- Switch, Params: 1600M, Release: Jan 2021
- GPT-3, Params: 175M, Release: May 2020
- T5, Params: 11M, Release: Oct 2019
- Megatron-LM, Params: 8.3M, Release: Sep 2019
- GPT-2, Params: 1.5M, Release: Feb 2019
- BERT, Params: 0.34M, Release: Oct 2018
- Transformer (big), Params: 0.213M, Release: Jun 2017
These models are shown as the red lines in the chart below, along with selected other models shown in blue.
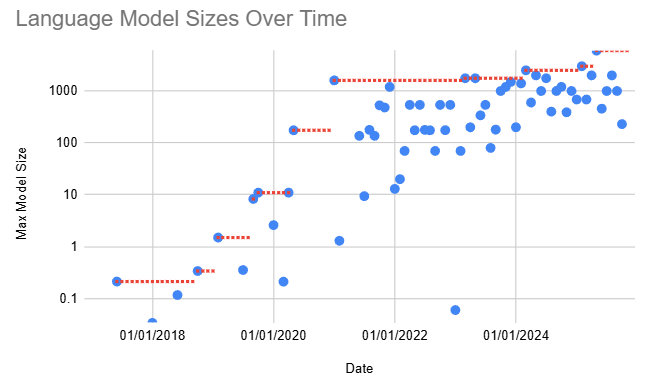
Note that the data for this article was taken from LifeArchitect.ai.
2017 – Transformer (0.2B)
Problem before: RNNs and LSTMs scaled poorly. Sequential dependency → O(sequence length) time per token, and gradients vanished over long contexts.
Scaling innovation:
- Self-attention: Replaces recurrence with full-sequence parallel operations. → Compute becomes O(n²) but fully parallelizable on GPUs.
- Layer normalization + residuals: Allowed much deeper networks to train stably.
- Multi-head design: Modularized capacity across subspaces of attention.
Result: Models could now scale vertically (deeper, wider) and horizontally (batch-wise parallel).
2018 – BERT (0.34B)
Problem before: Transformers trained from scratch on small supervised datasets quickly overfit.
Scaling innovation:
- Masked Language Modeling (MLM): Efficient semi-supervised pretraining. → Enables massive data-scale training.
- TPU infrastructure: Google’s first large-scale TPU pods allowed synchronized training across hundreds of accelerators.
- Mixed-precision training: Beginnings of FP16 / bfloat16 reduced memory footprint.
Result: Training hundreds of millions of parameters became routine.
2019 – Megatron-LM (8.3B) / T5 (11B)
Problem before: Single-GPU memory limits prevented models >1B parameters.
Scaling innovations:
- Tensor model parallelism: Split linear layers across GPUs (each GPU holds a shard of weights).
- Pipeline parallelism: Divide layers into stages across devices, overlapping forward/backward passes.
- Data parallelism improvements: Efficient all-reduce algorithms (e.g., NCCL) for gradient synchronization.
- TFRecord / data streaming: Input pipeline efficiency became critical for high-throughput training.
- Checkpoint sharding: Avoided duplicating optimizer states.
Result: Models jumped from 1B → 10B scale without exploding memory or I/O cost.
2020 – GPT-3 (175B)
Problem before: Even 10B-scale training was unstable (optimizer divergence, data throughput, compute waste).
Scaling innovations:
- Scaling laws discovery: Empirical laws (Kaplan et al.) allowed predictable scaling — enabling correct allocation of compute/data/model size.
- Adam optimization refinements: Stable mixed-precision FP16 + gradient clipping + dynamic loss scaling.
- Distributed training frameworks: DeepSpeed and Megatron-LM matured — combined tensor + pipeline + data parallelism.
- Massive data curation pipelines: Hundreds of billions of tokens (filtered Common Crawl, Books, Wikipedia).
- Infrastructure scale: Training on thousands of GPUs with model sharding, fused kernels, and activation checkpointing.
Result: Stable trillion-token-scale training with linear scaling of compute efficiency.
2021 – Switch Transformer (1.6T total parameters)
Problem before: Dense models → compute cost ∝ parameter count. Training 1T dense model would be economically infeasible. Scaling innovations:
- Sparse Mixture of Experts (MoE): Each token only activates 1–2 out of thousands of experts. → 100× increase in parameter count without 100× compute.
- Router network: Lightweight gating network selects active experts dynamically.
- Expert parallelism: Each expert resides on its own device group — allows scalable distributed memory use.
- Token-based load balancing: Avoids “hot experts” from overloading.
Result: Trillion-parameter models trained at roughly GPT-3 compute cost.
2023 – GPT-4 (1.7T est. cumulative)
Problem before: MoE models were hard to train (instability, routing collapse, communication overhead).
Scaling innovations:
- Hybrid architectures: Mix of dense core layers and sparse expert blocks → balance stability and efficiency.
- Advanced optimizer states sharding: ZeRO-3 (DeepSpeed) and FSDP in PyTorch.
- Custom interconnects (NVLink, Infiniband): Reduced gradient sync latency across 10k+ GPUs.
- Long-context attention (FlashAttention, rotary embeddings): Quadratic cost of attention reduced via kernel fusion and memory-efficient attention.
- Gradient checkpointing and recomputation: Memory savings by recomputing activations.
Result: 10× longer context, more efficient scaling to multi-trillion parameters (effective).
2024 – Claude 3 / 2025 – GPT-4.5 & Claude Opus 4
Problem before: Compute efficiency and memory bandwidth became the bottleneck, not just GPU count.
Scaling innovations:
- Dense–sparse hybrids: Different modules specialized (reasoning core, retrieval, vision, tool-use).
- Asynchronous mixture routing: Parallel expert inference without strict synchronization.
- Memory offloading (NVMe / CPU): Cold parameters stored off-GPU, streamed as needed.
- Speculative decoding & quantized inference: Reduced latency for large inference-time models.
- Custom training chips (TPU v5p, H100, GH200): Much higher interconnect and memory bandwidth.
Result: Trillion-parameter systems with near real-time inference became practical.
Summary
We can summarise the key innovations that led to the continually increasing model sizes below.
[Transformer (2017)] | |—> Enables deep, parallelizable architectures |—> Provides foundation for attention mechanisms | [BERT / Pretraining (2018)] | |—> Semi-supervised pretraining allows massive data scale |—> Requires TPUs / mixed precision for memory efficiency | [Megatron-LM / T5 (2019)] | |—> Model parallelism (tensor/pipeline) solves single-GPU memory bottleneck |—> Data parallelism + optimized all-reduce solves gradient sync bottleneck | [GPT-3 (2020)] | |—> Scaling laws + optimizer refinements allow stable training of 100B+ models |—> Massive curated datasets + infrastructure scale enable high data throughput | [Switch Transformer (2021)] | |—> Sparse Mixture-of-Experts (MoE) decouples parameter count from compute |—> Router networks + expert parallelism enable trillion-parameter models | [GPT-4 (2023)] | |—> Hybrid dense/sparse architectures stabilize MoE training |—> Memory-efficient attention (FlashAttention, rotary embeddings) reduces quadratic cost |—> Optimizer sharding (ZeRO/FSDP) + interconnect improvements allow multi-trillion-scale training | [Claude 3 / GPT-4.5 / Claude Opus 4 (2024–2025)] | |—> Dense-sparse modular design enables specialization (reasoning, retrieval, vision) |—> Asynchronous mixture routing + memory offloading solves latency & bandwidth issues |—> Speculative decoding + quantized inference allows efficient real-time deployment |—> Custom hardware (TPU v5p, H100, GH200) provides necessary compute density