
A commonly held belief is that reasoning is locked behind larger models. The idea is that larger models have more layers and wider layers which help them to better reason about relationships in text. This feels like a hand-wavy solution. For example, in a 2-hop reasoning problem, do you need 10 layers, but then for 4 hop, you need 20 layers? If your reasoning problem is more complex, do you need wider layers? As far as I know, none of these questions have good answers yet.
What we can at least do is study the differences between models architectures. The following figures contain architecture details for some of the SOTA models as well as family breakdowns for Gemma, Llama and Qwen; a few of the top open source models.
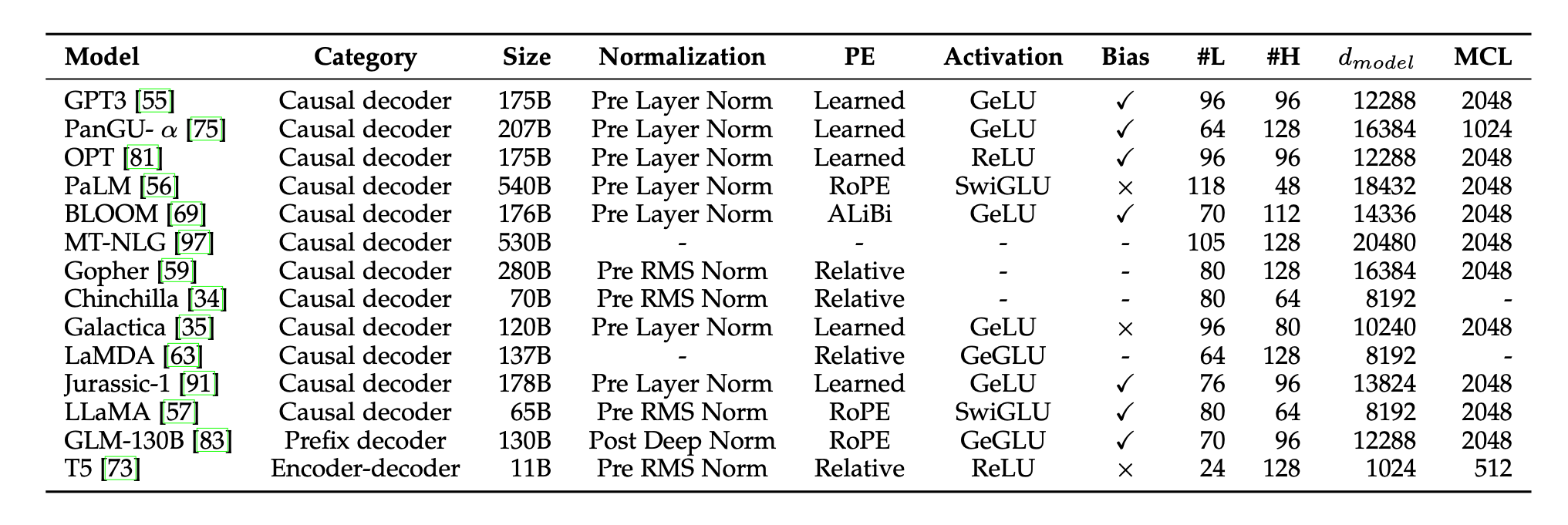
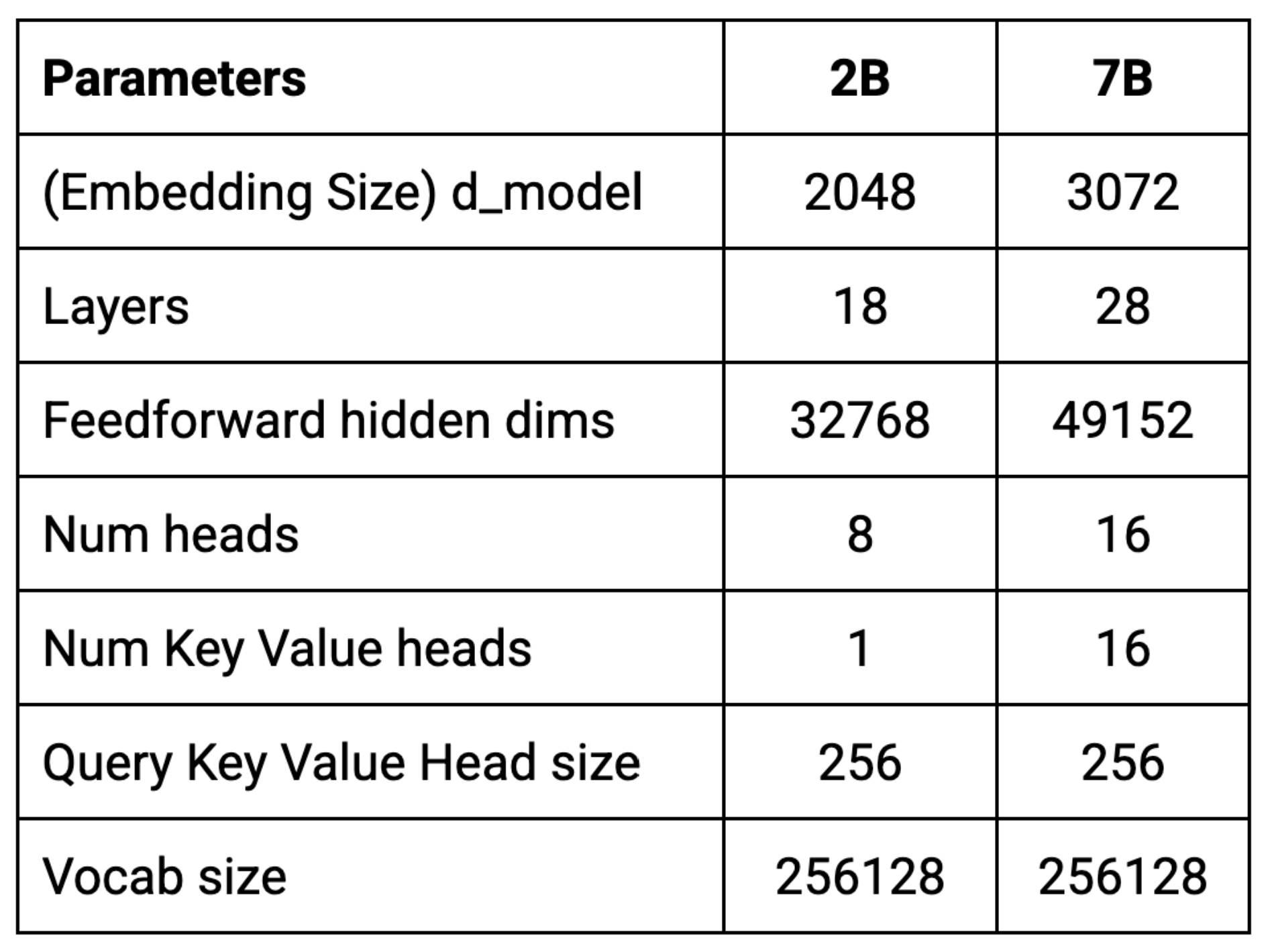

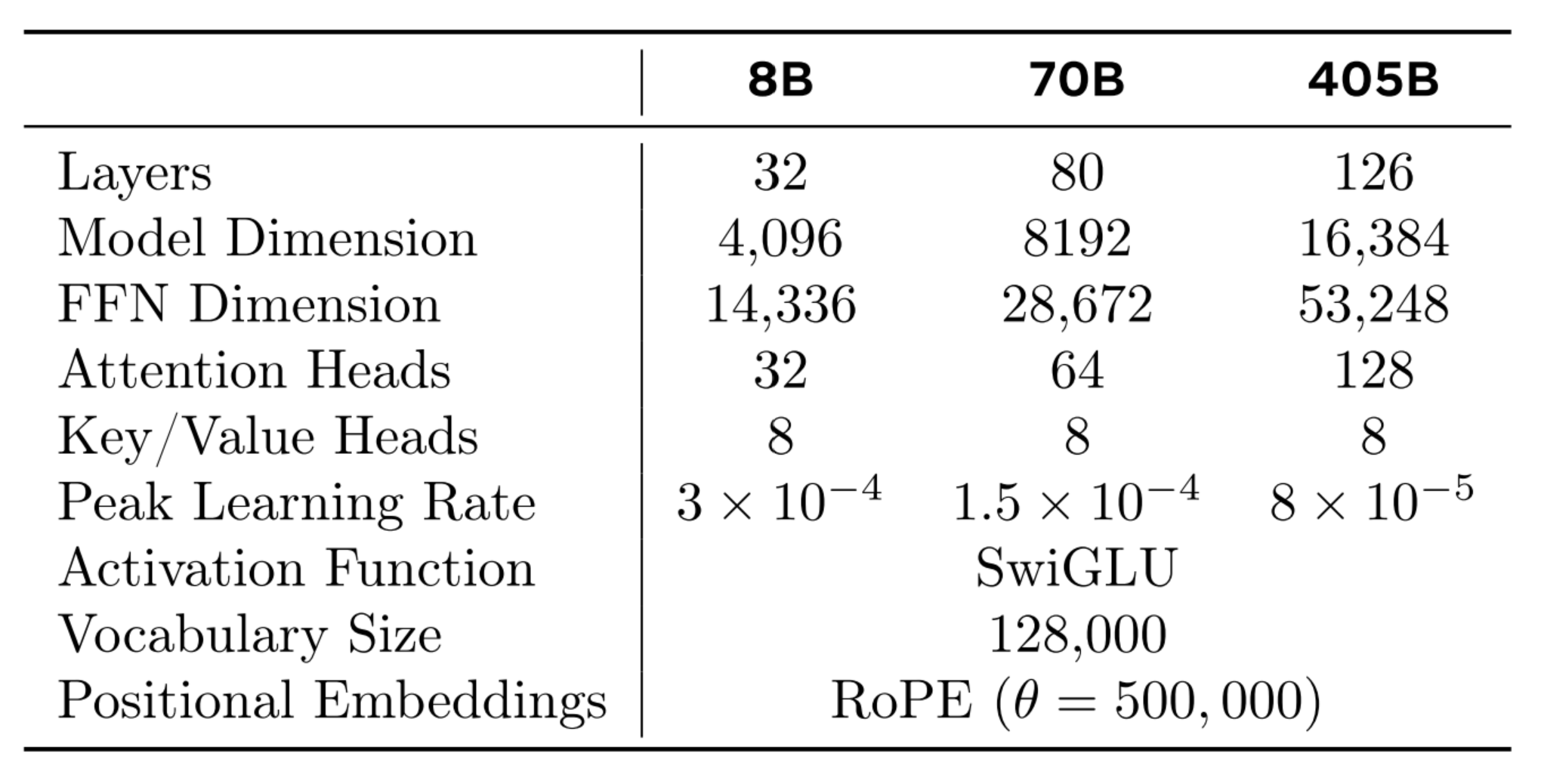
Observations:
- At the 7/8b model size, the number of layers is consistent at 28/32.
- As models got smaller, Qwen2.5 kept layer size high at 24 for their 0.5b model and 28 for 1.5b vs. 18 for 2b on Gemma.
I was somewhat inspired to look into this after reading through…