
Introduction
In reasoning chains, it’s important for LLMs to be able to keep track of different chains of thought, for better problem solving skills. On the other hand, smaller LLMs can struggle to answer previous asked questions if interrupted, even if instructed to do so. We model these tasks generated in reasoning chains as separate tasks that are passed to the model through instructions.
The key contributions can be summarised as follows:
- Benchmark for testing LLM’s ability to handle successive tasks while being interrupted.
- Evidence that various tiny LLMs perform very poorly on the benchmark, rarely referencing previous incomplete tasks, even when directly prompted to.
- Investigation of fine-tuning LLMs for this task: using a common RL approach showed some improvements on the benchmark.
Benchmark
The benchmark consists of sessions of successive questions with random interrupts during generation. The full definition of the benchmark is shown in Algorithm [1]. Questions are sampled from a simple set of tasks such as mathematical operations, translation, ordering. LLMs are directly prompted to answer previous tasks along with the current task. The interrupts are formed as maximum tokens passed to the generation method, typically in the range of 0 to 100.

An example of execution on the benchmark is shown below, with guiding system prompts excluded. The key metrics to track are:
- Accuracy: How many tasks the model gets correctly out of all tasks. Models are required to answer across multiple tasks to maximise this.
- Re-Attempts: How many tasks are re-attempted by the model. This is an indicator of whether the model is expressing the right behaviour of answering older questions.
B: <question task=1>What is the square root of 110?</question>
A: <thinking task=1>Square root of 100 is 10 and square root of 121 is 11, so it should be somewhere in between. Guess
B: <question task=2>What is the translation of "Bonjour" from French to English?</question>
A: <answer task=2>Hello</answer>
...
Training
A fine-tuning process was run on Llama-3.2-1B-Instruct, the best performing 1B model. Given no ideal dataset exists, RL-based learning was applied following Algorithm [2]. For model updates, a LoRA approach was chosen to significantly reduce the memory requirements. REINFORCE was used for calculating the model loss from rewards logits.

Results
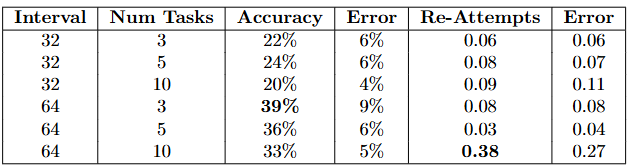
Varying benchmark configurations with a fixed LLM. It was clear that the larger the interval given, the higher the accuracy as the LLM had more time to think and answer. The LLM was also directionally more likely to re-attempt questions as the number of tasks increased, which is expected as it has more missed tasks. See Table [1] for details.
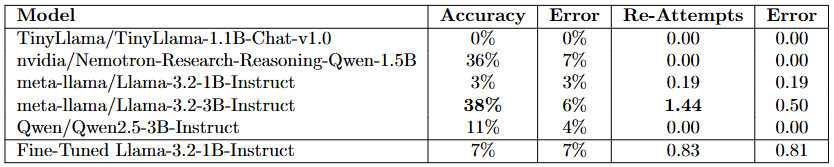
Varying LLMs with fixed configuration. The gaps between smaller and larger models was clear with 3B models significantly outperforming 1B models in their ability to answer previous questions. Llama3.2 was also seen to perform better overall compared to other models. See Table [2] for details.
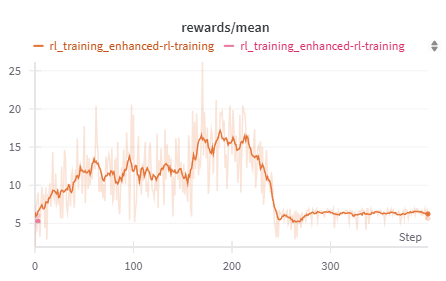
Fine-tuning of an LLM for the task. After running fine-tuning for 200 steps, the model was shown to be more likely to address previously asked questions, though this did not translate into significantly better accuracy. During training, model collapse was observed, preventing further improvement. Figure 1 shows the details.
Discussion
RAM limited throughput as it was expected to have 24GB RAM but access was limited to 8GB. This could only efficiently run models which are less capable (3B and below). This was especially a problem for training where the memory requirements increase significantly.
Prompting was shown to be effective at getting larger models to follow the required format and in some cases to reference previous tasks as seen in re-attempts.
Model size was a significant limitation in the work. Small models would often fail to match the structure or just be incapable of solving simple problems. Even if they could solve simple problems, the benchmark is designed for multi-step problems that can be interrupted and resumed.
We believe training results were not as good as expected due to compute limitations with respect to the task difficulty. It would have been more reasonable to aim for a simpler task. During training there was reasonable variance in rewards and the gradient updates were on the right order of magnitude.
Conclusion
Despite the limitations, it was still possible to see that models could be guided to respond across multiple instructions, though their latent ability is significantly limited. Training showed limited improvements suggesting an ongoing difficulty in working on more complex tasks with smaller models.