
Being reasonable can be hard. For LLMs it’s even harder.
Long reasoning chains, even if simple can lead to LLMs struggling to produce reasonable output.
We can run a simple test. Consider the following question:
If A is below B, B is below C, is A below C?
The answer is clearly, yes, and you’d expect an LLM to be able to work that much out. But what happens if we add more steps (e.g. “C is below D”) and even more. Does the LLM eventually fail?
Yes! At least, its performance gets worse. The model gets worse as the number of clauses increases (or length). Interestingly, it’s definitely not deterministic. With a length of 24, the LLM is still able to get it right 100% of the time. However, the overall trend is fairly clear, the longer the chain of tasks, the more likely it is to fail. Since it’s a yes/no question, we’d expect that a random model would score 50%. Given the small sample sizes it’s reasonable that it could drop to 0% sometimes.
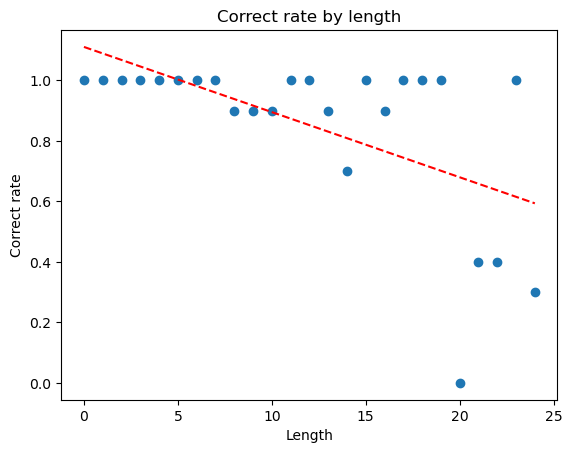
This is a fairly easy problem, and one you might even be able to guess. We can increase the difficulty and get a little more scientific.
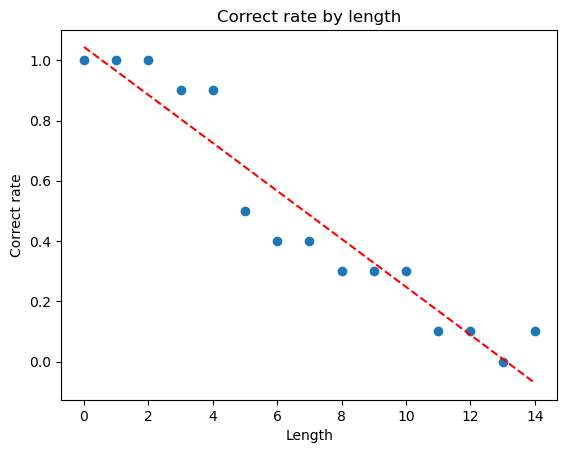
Firstly, we can shuffle the phrases so they’re not in order. This means the transformer must now pay attention across various parts of the text to do the reasoning.
We see below that pretty quickly that good performance turns to bad. The model is now beginning to fail only at length 5. It also consistently goes below 0. This suggests there’s some bias in the model that is making it more often than not suggest no (the answer should always be yes).
To confirm the above, we can adjust so the answer is yes or no equally. Indeed, we see that the model drops to an average of around 0.5.
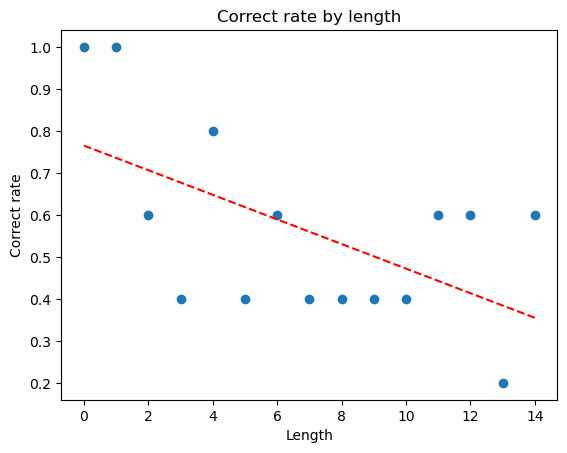
Finally, this was a 7b model with 10 tries per task. This model is great at many tasks, but we can see its reasoning capabilities are limited. Instead, testing on ChatGPT (Dec 2024), it is correct each of the few times tested with the length 25 problem.
So there’s still a long way to go for these small models. What exciting research is around the corner?